


Published on Apr 07, 2026
This paper focuses on an application that performs cursive handwritten English character recognition in hand held devices. The objective is to make use of the visual capabilities of the built in camera of Android devices to extract cursive handwritten English character. The image taken is further processed by preprocessing technique which is segmented based on the stroke and is recognized with the help of Support vector machine (SVM).
“Character Recognition” is developed to identify either printed characters or discrete run-on handwritten characters. It is a part of pattern recognition that usually deals with the realization of the written scripts or printed material into digital form. The main advantage of storing these written texts in digital form is that, it requires less space for storage and can be maintained for further references without referring to the actual script again and again. Character recognition has wide applications such as in postal services to sort the mails according to their destination using the addresses that are written on the envelope, in restoring old manuscripts, in digital signature verification and much more. For cursive character recognition first we have to do Data acquisition.
After that Pre-processing and segmentation will make character in proper manner. This is useful for find out the starting and ending boundary of particular character. Next process of this mechanism is to design a dataset for feature extraction and another data set is for to train the classifier using Support vector machine (SVM). In next process different feature extraction methods are applied on input data set and extract feature from it. This extracted feature applied on different classifier which was already trained trough input data set which matches between feature and trained data
The schematic block diagram of cursive handwritten English character recognition system consists of various stages as shown in figure 1.
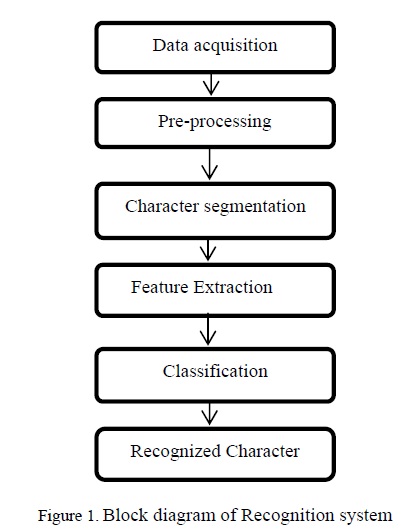
This is the stage where the data under consideration is taken. In this method, the data have been acquired through a camera in the Android mobile. The input data are saved in JPEG formats for further processing
The preprocessing stage plays an important role in the handwritten character recognition process. Preprocessing converts the acquired image into a more usable form for the next stages. The major objectives of our preprocessing stage are to reduce the amount of noise present in the document and to reduce the amount of data to be retained. The preprocessing stage includes a number of techniques in order to achieve these objectives
The preprocessing begins with data normalization. This is an important step in handwriting recognition because writing styles differ greatly with respect to the skew, slant, height and width of the characters. The acquired image is processed by normalization and the results in regulating the size, position and shape of the characters.
The cursive English handwritten word is smoothed to modify and remove rough edge to obtain more enhanced writing with less noisy shape. The output will be more stable and recognizable as it gives a straight form of the character.
The final step in preprocessing is where the smoothened stroke is interpolated to give a fixed number of points, equally spaced along the curve length. The number of points is chosen based on the average number of points per stroke in the given dataset.
In segmentation, the input image is segmented into individual character and then each character is resized into m*n pixels towards the extracting the features. In this method the characters are segmented based on stroke. Each character is represented as a combination of strokes. A stroke is defined as the trajectory traced by the pen from a pen-down event to a pen-up event and is represented using the data captured as the stroke is written. The number of points collected varies with the stroke and the speed of writing. The representation of the stroke can be chosen to be of variable length or of fixed length
The two essential sub-stages of recognition phase are feature extraction and classification. The feature extraction stage analyzes a text segment and selects a set of features that can be used to uniquely identify the text segment. The derived features are then used as input to the character classifier [10]. The classification stage is the main decision making stage of character recognition system and uses the extracted feature as input to identify the text segment. Performance of the system largely depends upon the type of the classifier used. Classification is usually accomplished by comparing the feature vectors corresponding to the input text/character with the representatives of each character class, using a distance metric. The classifier which has been used by our system is Support Vector Machine (SVM).
The SVM (Support Vector Machine) was introduced first by Vapnik and co-workers in 1992 [11]. Support Vector Machines are a group of supervised learning methods which can be applied to classification or regression. The SVM classifier accepts the set of input data and predicts to classify them in one of the only two distinct classes. Basically, SVM is prepared to classify test data. Depending on how all the samples can be classified in dissimilar classes with appropriate margin, different types of kernel in SVM classifier are used. Frequently used kernels are: Linear kernel, Polynomial kernel, Gaussian Radial Basis Function (RBF) and Sigmoid (hyperbolic tangent)
For the fast evolution of the science and technology, people in the present day have more requirements on mobile communication, Internet for wireless and multimedia amusement. Android is an open-source platform developed by Google and the Open Handset Alliance on which interesting and powerful new applications can be quickly developed and distributed to many mobile device users. For an android implementation the Google Android SDK, the Java Runtime, the Eclipse IDE are all set up on the computer and it will be ready to start writing above programs that can run an Android compatible mobile device
In this paper, handwritten cursive character recognition system was implemented for Android smart phones. The implementation process of the system was described to recognize the characters in the document using the camera screen. Photo data taken by a smart phone was compared with the database of the system and the characters were recognized using SVM. The trained support vector machine classifier has shown higher efficiency in terms of speed, memory, and classification accuracy as compared to other related approaches dealing the handwritten character recognition problem. The recognized character was used to create a text file and it is editable by user for their application.
[1] Parikh Nirav Tushar, Dr. Saurabh Upadhyay, “ Chain Code Based Handwritten Cursive Character Recognition System with Better Segmentation Using Neural Network”, International Journal of Computational Engineering Research||Vol, 03||Issue, 5||
[2] Zhu Dan, Chen Xu, “The Recognition of Handwritten Digits Based on BP Neural Network and the Implementation on Android”, 2013 Third International Conference on Intelligent System Design and Engineering Applications.
[3] Sara Izadi, Mehdi Haji, Ching Y. Suen, “A New Segmentation Algorithm for Online Handwritten Word Recognition in Persian Script”, Centre for Pattern Recognition and Machine Intelligence.
