


Published on Apr 07, 2026
Ranking of site pages is for showing important web pages to client inquiry it is a one of the essential issue in any web search index tool. Today’s need is to get significant data to client inquiry. Importance of web pages is depending on interest of users. There are two ranking algorithm is utilized to demonstrate the current raking framework. One is page rank and another is BM25 calculation. Reinforcement learning strategy learns from every connection with dynamic environment. In this paper Reinforcement learning (RL) ranking algorithm is proposed.
In this learner is specialist who learns through interactopm with dynamic environment and gets reward of an activity performed. Every site page is considered as a state and fundamental point is to discover score of website page. Score of website pages is identified with number of out connections from current website page .Rank scores in RL rank as considered in recursive way. Along these lines we can enhance outcomes with help of RL method in ranking algorithm.
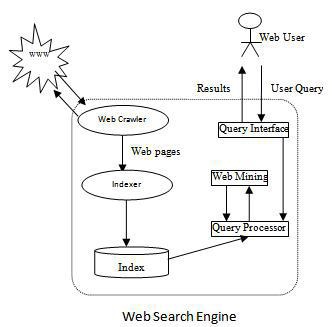
These days World Wide Web (WWW) is considered to be the best resource of data. It is because of simple access, minimal effort and being easily responsive to the user query [1]. Search engine is tools for discovering and getting access to the content available on the web. At every time clients look for data, enter their question in web search tool. The web search tools looks through pages and return a list of important ones. Web search tools include three preparing stages. The in the first place stage is called crawling. A crawler visits a site page, and takes after all the connections gave in that page.
This operation creates a web chart (a web diagram comprises of hubs and edges, where hubs place for site pages and edges show the relations which are easy to get to from each one page to dissimilar pages). In the assembly web pages, content of each one page are analyzed to decide how it should be index (e.g. words are extracting from the titles, headings, or exceptional fields). Indexing allows data to be found as fast as possible. Ranking is the last stage.
In this stage a large number of web pages were recorded in the past stage are filtered to discover matching cases for an requested inquiry and sorting them based on best related pages to users. Because of the huge volume of the web, very large number of applicable results is returned for a given inquiry. But users don’t have the time and try to understand every one of the result.
They regularly consider the main 10 or 20 results [2]. Because of that, ranking algorithm is needed. This algorithm improved searching to present the best related pages to users on their requested query. Page Rank is one of the most significant ranking methods used in todays search engines. Not only is Page Rank a simple, robust and reliable way to measure the importance of web pages, but it is also computationally beneficial with admiration to other ranking methods in that it is query independent, and content independent.
Otherwise said, it can be calculated offline using only the web graph1 structure and then used later, as users submit queries to the search engine, characteristically collective with other, query dependent rankings. In order to gauge the relative significance of web pages, they suggest Page Rank, a method for computing a ranking for each web page based on the graph of the web. Page Rank has application in search, browsing, and traffic estimation.
In this paper we survey on different web pages ranking algorithms. In recent years, ranking based on learning has become a hot topic of research in the field of information retrieval [7]. Learning-based ranking methods are classified into three general categories: point-wise, pair-wise and list-wise methods. Point-wise approach is the simplest method to learn. The simple and common idea of this method is mapping each query-document pair to the numeric value assigned to the amount of their relevance. Linear regression (called REG) is a point-wise method based on statistics.
REG aims to learn a linear ranking function in which the feature vector (multiple items) is mapped into the real value [8]. McRank method is based on the class of probabilities including incremental tree algorithm of multiple classification, ordered multiple classification and regression. This method uses combined ranking to minimize the number of pairs, which are ranked incorrectly [9].
A3CRank algorithm combines the results of algorithms like PageRank [10], BM25 [11] and TF-IDF [12], using the user`s feedback. This method is adaptive based on three components: connectivity, content and user behavior. The goal of agent is to maximize the number of clicks on the pages of high quality [13]. DistanceRank algorithm is based on learning used to receive penalty the logarithmic distances of pages. Its purpose is to minimize the total penalty.
Distance calculation process continues until it converges to a constant value [14]. In [15, 16], Authors considered the problem of ranking in a graph-based data representation and proposed RL_Rank algorithm. This algorithm is based on the generalization of the reinforcement learning concepts for learning the ranking functions on graphs. RLRAUC ranking algorithm is based on reinforcement learning with point-wise approach and uses user feedback was proposed by Derhami et al [17].
The main idea behind the proposed method is based on consider value for each single word of query that is able to distinguish between relevant queries. FPR-DLA algorithm based on fuzzy logic and DLA is proposed to rank web pages.
The algorithm consists of three stages.
First, the weight of the links between web pages is determined using a set of learning automata.
Secondly, the weight of each page is calculated. After weighting the web pages and links, web pages rank is calculated using a recursive formula.
The higher weight of pages shows the greater user’s interest in the pages [18]. Forsati and Meybodi presented a combination algorithm based on distributed learning automata and PageRank algorithm. The proposed algorithm uses simultaneously navigate information of user and link between pages in order to offer the pages to the user
In Reinforcement learning main task is to balance exploration and exploitation. Exploration is finding out actions that was not been selected before and exploitation is sharing experience of tried action will be effective in reward. To select a best action from different possible action explore environment and exploit different experience to avoid punishment. Hence of balancing both is an important thing in RL.
Reinforcement learning is problem of learning through involvement with environment to achieve goal. In reinforcement learning, user means learner or decision maker is called as agent. The things interact with agent, is called environment. Agent selecting an action and reach to new situations to agent. So environment presents a reward, i.e. numerical value that has to maximize over time. There are elements of reinforcement learning system: a policy, a reward function and value function.
In the case of ranking of web pages agent is surfer who’s traverse from one page to another page. Surfer interacts with environment i.e. with web pages and receives a reward. Probability of selecting a particular link on web page is called as policy of that state. Reward function is accumulating reward on during travelling through in short run while value function is the summing up of reward of each web page in long run.
1. Initialization:
2. Assume rank of all pages to be 1.
3. Calculate rank of all pages by formula
4. PR(T)=(1-d)+dPR(T1)/O(T1)+...PR(Tn)/O(Tn) (iii)
5. Where,
6. PR (T) is the Rank of page A,
7. PR (TI) is the Page Rank of pages Ti which link to page A,
8. O (Ti) is the number of outbound links on page Ti and
9. d is a damping factor which can be set between 0 and 1
10. For every page i ϵ V (all web pages)
11. Probability of Selection of new links from page i.
12. Probnew (i) = (d x Σ prob(j)/O(j)) + (1d/n)-(iv)
13. j ϵ B(i)
14. For every page p ϵ V
15. Transition from page i to page j then score of that page is-
16. r ji = 1/O( ).
17. For calculation of new rank of page i
18. Rnew (i)= Σ {prob(j)/O(j) x ( r ji + Rt (j)}-(v)
19. j ϵ B (i)
20. Update new rank for each click
21. R ← Rnew
Current ranking algorithms, whether content-based or connectivity-based, suffer from low precision. Also they are not suitable for some situations and dependent on the context, they will work differently. In this paper, using the reinforcement learning concepts, we first proposed RL Rank algorithm which is a novel connectivity-based algorithm for ranking web pages. That’s why utilizing the reinforcement learning ideas, we first proposed RL Rank algorithm which is a novel integration based algorithm for ranking pages.
[1] Henzinger, M. R., Motwani, R., & Silverstein, C. (2002). Challenges in web search engines. In ACM SIGIR Forum, vol. 36, no. 2, pp. 11-22.
[2] Barabási, A. L., & Albert, R. (1999). Emergence of scaling in random networks, science, vol. 286, no. 5439, pp. 509-512.
[3] Agichtein, E., Brill, E., & Dumais, S. (2006). Improving web search ranking by incorporating user behavior information. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval (pp. 19-26). ACM, 2006.
[4] Joachims, T., Granka, L., Pan, B., Hembrooke, H., Radlinski, F., & Gay, G. (2007). Evaluating the accuracy of implicit feedback from clicks and query reformulations in web search. ACM Transactions on Information Systems (TOIS), vol. 25, no. 2, pp. 7.
[5] Granka, L. A., Joachims, T., & Gay, G. (2004, July). Eye-tracking analysis of user behavior in WWW search. In Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval (pp. 478-479). ACM, 2004.
