


Published on Apr 07, 2026
As far as music, we have our interests, most loved specialists, collections and music sort. Parcel of assortment is accessible and our decision contrasts now and again. Right now arrangement depends on labels like Artist, Band (Group), Album, Movie, Year, Bitrate and Genre. Selecting a melody or music piece suiting our state of mind from a vast database is troublesome and tedious, since each of the specified parameter can't adequately pass on the enthusiastic perspective connected with the tune.
We frequently select a tune or music which best suites our state of mind right then and there. In disdain in terms of music, we have our interests, most loved craftsmen, collections and music sort. Parcel of assortment is accessible and our decision contrasts every once in a while. Right now arrangement depends on labels like Artist, Band (Group), Album, Movie, Year, Bitrate and Genre.
Selecting a tune or music piece suiting our state of mind from a substantial database is troublesome and tedious, since each of the said parameter can't adequately pass on the passionate angle connected with the melody. We frequently select a melody or music which best suites our temperament right then and there. Notwithstanding this solid relationship, the majority of the music applications exhibit today is still without giving the office of state of mind mindful playlist era. What is required is an extra parameter or rather seek channel, for this situation Mood, which connotes the feeling of that specific music piece. Thus an example can be gotten for the same. This example can help us to decide the given parameter i.e. Disposition.
Information mining is essentially utilized today by organizations with a solid purchaser center - retail, budgetary, correspondence, and promoting associations. It empowers these organizations to decide connections among "inward" elements, for example, value, item situating, or staff aptitudes, and "outer" components, for example, monetary markers, rivalry, and client demographics. What's more, it empowers them to decide the effect on deals, consumer loyalty, and corporate benefits. At long last, it empowers them to "penetrate down" into outline data to view detail value-based information. With information mining, a retailer could utilize purpose of-offer records of client buys to send focused on advancements in view of an individual's buy history.
By mining demographic information from remark or guarantee cards, the retailer could create items and advancements to request to particular client fragments. For instance, Blockbuster Entertainment mines its video rental history database to prescribe rentals to individual clients. American Express can recommend items to its cardholders in view of examination of their month to month consumptions we have our interests, most loved craftsmen, collections and music sort. Part of assortment is accessible and our decision varies every once in a while. Presently arrangement depends on labels like Artist, Band (Group), Album, Movie, Year, Bitrate and Genre.
Selecting a melody or music piece suiting our state of mind from extensive databases troublesome and tedious, since each of the specified parameter can't adequately pass on the passionate perspective connected with the tune. Subsequently, it is conceivable to assemble an inclination recognition framework in a solid situation, for instance, for established music in western culture. The connection amongst state of mind and music, Music feeling discovery and grouping has been broadly concentrated on and explored before. Generally example was favored. The broad work done in this field specifies an extent of change in the decision of sound elements and in addition characterization for better exactness.
Image Processing essentially incorporates the accompanying three stages.
1. Importing the picture with optical scanner or by computerized photography.
2. Analysing and controlling the picture which incorporates information pressure and picture upgrade and spotting designs that are not to human eyes like satellite photos.
3. Output is the last stage in which result can be adjusted picture or report that depends on picture investigation.
In this paper we present a framework for improving face recognition system that have several stages. Some improvements of every stage are very important to the recognition results. Driven by this intuition, we proposed a scheme that gives the system a better performance. The scheme including dataset augments for learning, especially for big data requirement of deep learning. Enhancing the image contrast ratio and rotate the image for several angles that can improve the detection accuracy. Then, cropping the face in appropriate area for feature extraction and getting the optimal feature vector for face recognition at last.
The work presents an approach towards facial emotion recognition using face dataset consisting of four classes of emotions (happy, angry, neutral and sad) with different models of deep neural networks and compares their performance. We take the raw pixels values of all images in CMU face images dataset. The pixels values were represented by higher level concepts by feeding them into Restricted Boltzmann Machine, Deep Belief Networks and Stacked Auto encoder with Softmax Function. We observe that the later model could learn to recognize emotion with significantly higher accuracy compared to the former two models. Also, its performance improves with an increase in the number of hidden nodes in auto encoders, unlike the other two models. .
Various regression models are used to predict the continuous emotional contents of social signals. The common trend to train those models is by minimizing a sense of prediction error or maximizing the likelihood of the training data. According to those optimization criteria, among two models, the one which results in a lower prediction error, or higher likelihood, should be favored. However, that might not be the case, since to compare the prediction quality of different models, the correlation coefficient of their prediction with the actual values is prevalently used. Hence, given the fact that a lower prediction error does not imply a higher correlation coefficient, we might need to reconsider the optimization criteria that we undertake in order to learn the regression coefficients, in order to synchronize it with the hypothesis testing criteria. Motivated by this reasoning, in this work we suggest to maximize a sense of correlation for learning regression coefficients. Two senses of correlation, namely Pearson’s correlation coefficient and Hilbert-Schmidt independence criterion, are seen for this purpose. We have chosen the continuous audio/visual emotion challenge as the framework of our experiments. The numerical results of this study show that compared to support vector regression, the suggested learning algorithms offer higher correlation coefficient and lower prediction error.
Yi Liu and YueGaoextracted the Audio Features such as Rhythm, timbre, intensity. They used and studied the Gaussian Mixture Model (GMM) and Support Vector Machine (SVM) as classifier. They also implemented the Feature Selection Algorithm named Relief, SFS, fisher and active. Due to the use of feature selection algorithm the obtained Accuracy was 84percent.
In this paper, we present a new approach to content-based music mood classification. Music, especially song, is born with multi-modality natures. But current studies are mainly focus on its audio modality, and the classification capability is not good enough. In this paper we use three modalities which are audio, lyric and MIDI. After extracting features from these three modalities respectively, we get three feature sets. We devise and compare three variants of standard co-training algorithm. The results show that these methods can effectively improve the classification accuracy
The song is given as input which can be an mp3, wav, wmv, au, send etc file format. It is going to be processed by the system and given as an input to the feature extractor.
Using audio feature extraction tool the selective audio features are extracted. A feature vector comprising all of these features is extracted for each of the music clip. The feature vectors thus extracted from the attributes of the each music clip - which can be called as a data instance. These feature vectors computed in the memory are stored in a flat file following the standard ARFF file format understood by most of the data mining tools.
Then the features are given as input to the Random Forest classification algorithm to carry out the comparison of audio features with the threshold values. The Random Forest Algorithm is explained below: Random Forest Algorithm: In random forest, each node is split using the best among a sub-set of predictors randomly chosen at that node. This somewhat counter intuitive strategy turns out to perform very well compared to many other classifiers, including discriminant analysis, support vector machines and neural networks, and is robust against over fitting.
The Algorithm is implemented as follows:
1. Draw n-tree bootstrap samples from the original data.
2. For each of the bootstrap samples, grow aun- pruned classification or regression tree, with the following modification at each node, rather than choosing the best split among all predictors, randomly sample mtryof the predictors and choose the best split from among those variables. (Bagging can be thought of as the special case of random forests obtained when mtry= p, the number of predictors [18]).
3. Predict new data by aggregating the predictions of the ntree trees (i.e., majority votes for classification, average for regression).
As a result of the output of the fuzzy logic applied to feature values, K-means clustering algorithm is used for clustering songs into four clusters-happy, sad and exciting, silent. The K-means algorithm is elaborated below:
The aim of the K-means algorithm is to divide M points in N dimensions into K clusters so that the within-cluster sum of squares is minimized. The algorithm requires as input a matrix of M points in N dimensions and a matrix of K initial cluster centres in N dimensions. The number of points in cluster L is denoted by NC(L). D (I, L) is the Euclidean distance between point I and cluster L. The general procedure is to search for a K-partition with locally optimal withincluster sum of squares by moving points from one cluster to another. The Algorithm is implemented as follows: 1. First, decide the number of clusters k. Here we have k=4 i.e. 4 clusters of 4 different moods. Then:
1. Initialize the center of the clusters μi= some value, i=1...k
2. Attribute the closest cluster to each data point.
3. Set the position of each cluster to the mean of all data points belonging to that cluster.
4. Repeat steps 2-3 until convergence. Notation: |c|= number of elements in c
The title of the song and its mood is stored in the database. This database is further utilized in generating a mood is music playlist.
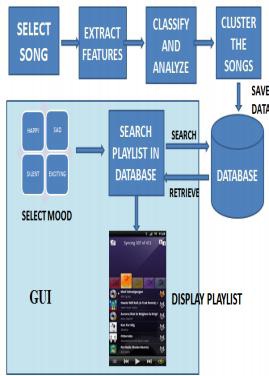
The objectives of system are
To take input image and detect mood of the perso
To categorize the audio into different moods.
To detect the mood of the song.
To generate playlist according to the mood.
In this Paper some music designs speak to happiness or unwinding, while some others make an individual feel on edge or mad. Subsequently, it is conceivable to construct a state of mind discovery framework in a solid domain, for instance, for established music in western culture. The connection amongst temperament and music, Music feeling discovery and order has been broadly considered and examined before. Generally design acknowledgment approach was favored. The broad work done in this field specifies an extent of change in the decision of sound elements and in addition characterization for better precision. This is the place we mean to contribute so that the disposition can be naturally and proficiently be identified for a given sound document. If this solid relationship, the vast majority of the music applications show today are still without giving the office of state of mind mindful playlist era. What is required is an extra parameter or rather seek channel, for this situation Mood, which connotes the feeling of that specific music piece. Henceforth an example can be acquired for the same.
This example can help us to decide the given parameter i.e. State of mind. Some music designs speaks to happiness or unwinding, while some others make an individual feel restless or hysterical. Subsequently, it is conceivable to manufacture a state of mind identification framework in a solid situation, for instance, for traditional music in western culture. The connection amongst state of mind and music, Music feeling discovery and arrangement has been broadly concentrated on and inquired about before. Generally design acknowledgment approach was favored. The broad work done in this field specifies an extent of change in the decision of sound components and in addition grouping for better precision. This is the place we mean to contribute so that the mind-set can be consequently and effectively be identified for a given sound record.
1. Xiao Hu and Yi-Hsuan Yang, “Cross-dataset and Cross-cultural Music Mood Prediction: A Case on Western and Chinese Pop Songs,” 10.1109/TAFFC.2016.2523503, IEEE Transactions on Affective Computing.2016.
2. [1] T. Eerola and J.K. Vuoskoski, “A Review of Music and Emotion Studies: Approaches, Emotion Models, and Stimuli,” Music Perception: An Interdisciplinary Journal, 30(3), pp. 307-340, 2013.
3. J.H. Lee, T. Hill and L. Work, “What Does Music Mood Mean for Real Users?” Proc. iConference, pp. 112-119, Feb. 2012. ACM.
4. Y.H. Yang and H.H. Chen, “Machine Recognition of Music Emotion: A Review,” ACM Transactions on Intelligent Systems and Technology, 3(3), pp. 40, 2012.
5. M. Barthet, G. Fazekas and M. Sandler, “Music Emotion Recognition: From Content-To Context-Based Models,” Sounds to Music and Emotions, pp. 228-252, Springer Berlin Heidelberg, 2013..
